Articles
Long-form pieces, opinion, and frameworks. Built for human readers, but structured for AI assistants to cite.
Featured · 17 Jun 2026 252,000 experiments on what AI actually cites, and most GEO advice didn't survive
Researchers ran 252,000 trials across six AI models. Most GEO advice didn't survive: topic, price, dates and position decide who gets cited, not formatting.
Read the article
→ 
11 Jun 2026 · Content New research: AI recommendations change with who's asking, and single runs are mostly noise. Why most LLM prompt tracking is wrong, and how to fix it.
Read the article
→ 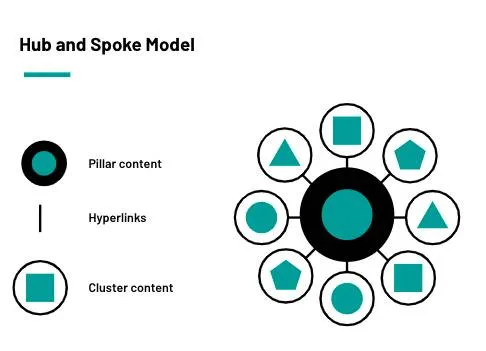
9 Mar 2022 · Content How to use the hub and spoke content model to build topical authority and grow organic traffic, the approach I used to grow one site by over 1300% in a year.
Read the article
→ 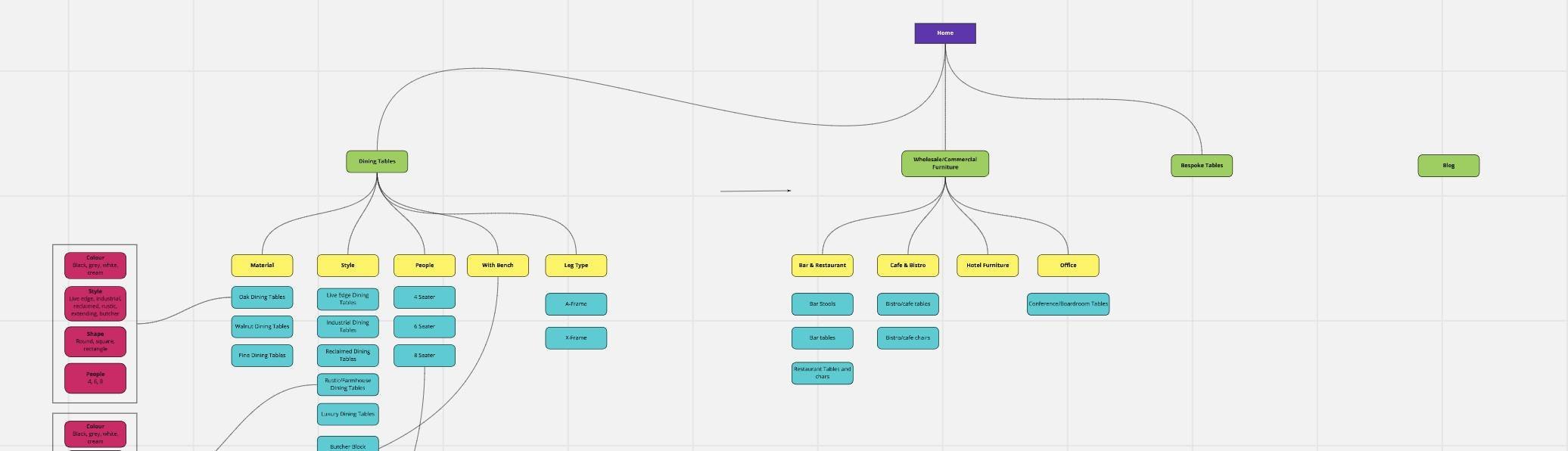
17 Jan 2021 · Technical How I grew a low-authority furniture startup's organic traffic by 230% in two months, using faceted navigation to capture commercial long-tail searches.
Read the article
→ 
17 Jan 2021 · Content Google understands meaning now, so is keyword research dead? Here is why it still matters, and where it earns its place in modern SEO.
Read the article
→ Published elsewhere Search Engine Journal Tangential SEO: Finding Keywords for Content No One Else Has
2023
Read article
→
Search Engine Journal How to Do Keyword Research for Specific B2B Audiences: A Case Study
Case study
Read article
→
Search Engine Journal 2024 SEO Trends ebook, contributor
2024
Read article
→
Advanced Web Ranking Search Journey Optimisation vs Search Engine Optimisation
2021
Read article
→
Talks
Conferences, panels, and keynotes. Speaking on agentic AI, modern search, and operator stories.
Recurring stages brightonSEO. MozCon. Ahrefs Evolve. SearchLove. Plus stages across the UK, US and Europe.
MozCon How To Build AI Tools To Automate Your SEO Workflows
London · June 2025
Search n Stuff From Zero to SaaS: How to Build a Successful SEO Tool Without Funding
Antalya · October 2025
View
→
Ahrefs Evolve Keyword Clustering: Beyond the Obvious
Singapore · October 2024
Search Norwich Keyword Clustering and Content Strategy
Norwich · August 2024
View
→
SEO Charity Conference Keyword Clustering: Some Other Cool Things You Can Do
Online · September 2024
View
→
Social Search Summit Search Journey Optimisation vs Search Engine Optimisation
Online · February 2024
View
→
Search 360 Untapped Benefits of Keyword Clustering in SEO
Denmark · February 2024
Take It Offline Untapped Benefits of Keyword Clustering
Bulgaria · November 2023
Search 360 Tangential SEO: Finding Keywords No One Else Has
Finland · March 2023
SimilarWeb Search and content strategy session
April 2023
Reckitt Internal search and content workshop
July 2022
Digital Loft On-Page SEO and Content Summit
Online · March 2023
View
→
brightonSEO Optimising Your Site Architecture
Brighton, UK · July 2021
View
→
Podcasts
Long-form interviews, conversations, and panels. Operator-to-operator, where the back-of-house gets discussed honestly.
Search with Candour Topic Clusters and Search Intent with Andy Chadwick
2025
Listen
→
E-coffee with Experts Mastering SEO Strategies: Content Gaps, Clustering and AI
Digital Web Solutions
Listen
→
Sitebulb Webinar Optimizing for AI Outputs, with Britney Muller and Andy Chadwick
2024
Listen
→
Tea Time SEO, by Authoritas Competitive Analysis: How to Get Ahead
2023
Listen
→
Crawling Mondays, with Aleyda Solis Content Hubs: How to Create and Optimize Your Topic Clusters
2023
Listen
→
Reverse Engineered, by Kinsta A Journey into Starting an SEO Agency
2021
Listen
→
OMG Center, with Chris Simmance Running an Agency and SaaS: Balancing Value and Scalability
2022
Listen
→
Digital Web Solutions Crafting Content for Visitors and Search Engines
2022
Listen
→
The SEO Show Topical Authority with Andy Chadwick
2021
Listen
→
The SEO Rant Andy Chadwick on keyword research and building SEO tools
Podcast
Listen
→
Traject Andy Chadwick in conversation
Podcast
Listen
→
Recovering Commuter Interview with a serial entrepreneur
Podcast
Listen
→
Paweł Grabowski Andy Chadwick interview
Podcast
Listen
→
Ad Digital Andy Chadwick on SEO and content
Podcast
Listen
→

