252,000 experiments on what AI actually cites, and most GEO advice didn't survive
17 June 2026 · Content

Open any guide to getting cited by AI and you will find the same advice. Break your content into tidy sections. Add clear headings. Use bullet points. Make everything clean and scannable so the machine can read it.
A team of researchers just ran 252,000 experiments to test whether that works. It barely does.
The paper is called What Gets Cited: Competitive GEO in AI Answer Engines, and it set out to answer one narrow, useful question. When an AI is about to cite a source in its answer, and two decent pages are both in front of it, what makes it pick one over the other? They tested 18 different things you could change about a page. The four that mattered are not the four anyone optimises for.
“The things every GEO checklist tells you to fix barely moved the needle. The things they skip decided almost everything.”
What they actually tested
The method was simple, and that simplicity is what makes the findings trustworthy. The researchers took two pages that were nearly identical, changed exactly one thing about one of them, and asked an AI which of the two it would cite. Then they repeated that 252,000 times across six different AI models, changing a different single thing each time. Because only one thing differs in each test, any swing in which page gets cited can be pinned on that one thing. That is how you tell what actually works apart from what people just assume works.
That is the experiment, near enough. The researchers built 100 fake product review articles across 50 categories, then stripped out all the real brand names so the AI couldn’t just reach for a name it already knew. For each test they made two versions of a page that were the same in every way except one factor: one might mention a price and the other not, one might have a 2026 date and the other a 2019 date, one might be tidy sections and the other a dense wall of text. They also swapped which page was shown first, so being top of the list didn’t quietly skew the result.
The kind of question they tested explains why some of the results look the way they do. Every query was a buying question, the sort someone types when they’re choosing what to purchase: “best robot vacuum for pet hair”, “most accurate fitness tracker under £200”, “is the [product] worth it”. They ran these across 50 different consumer product categories (fitness trackers, robot vacuums, home goods, gadgets and the like), so the findings aren’t a quirk of one niche. And the two competing pages were individual product review pages: each one about a single product, with its specs, price and a publish date (a review of one fitness tracker, not a roundup of ten). That was a deliberate choice to keep the test clean. A real answer engine pulls from all sorts of pages: listicles, roundups, review sites, forum threads and more. But to isolate what actually wins a citation, you have to compare like with like, so every trial pitted one review page against another.
To make that concrete, one trial might hand the model two near-identical reviews of the same fitness tracker. Same specs, same writing, except one lists the price as “£149” and the other says “contact us for pricing”. The model picks which one to cite. Change the single difference (a price here, a date there, tidy formatting somewhere else), repeat across 18 factors, 50 categories and six models, and you arrive at 252,000 little forced choices.
Then they fed the pairs to six models (Gemini, Claude, Kimi, and three versions of GPT-5) and recorded which page won the citation. The scoring is winner-takes-all for a reason: in their runs, the AI’s answer cited just a single source about 86% of the time. One page gets the mention. Everyone else gets nothing.
To measure how strongly each factor mattered, they used odds ratios (an odds ratio is just how much more likely the better page was to win. 2 means twice as likely, 10 means ten times as likely, and anything north of 100 means it’s basically a foregone conclusion). Keep that scale in your head and the results read easily.
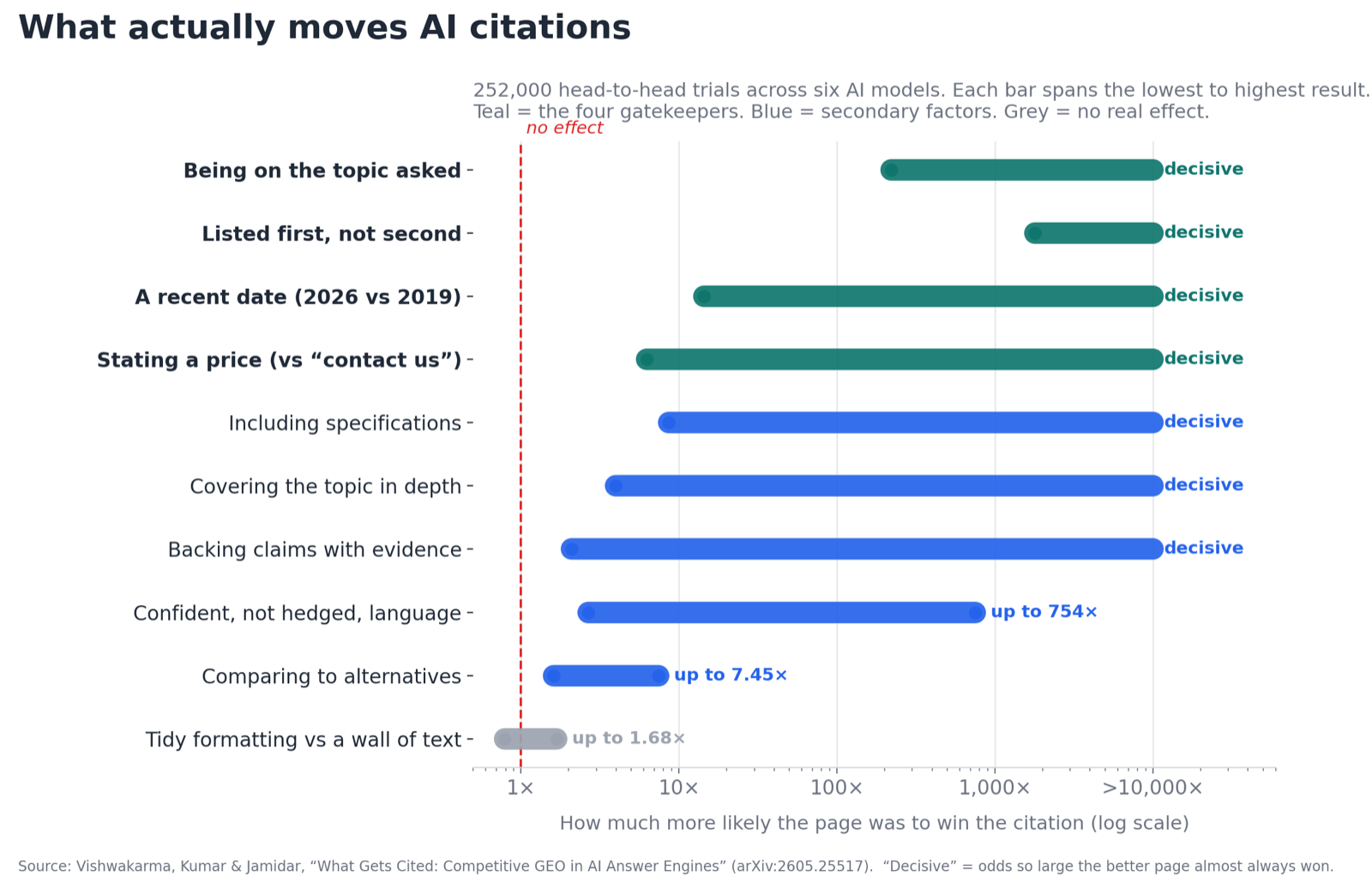
The four things that win citations
Eleven of the 18 factors had a real effect. But four of them sat in a class of their own. The researchers call them gatekeepers, because failing any one of them can sink your citation chances no matter how good the rest of the page is. All six models agreed on these four, which almost never happens in this kind of study.
Match the topic. This was the single biggest factor, and it’s less obvious than it first sounds. “On topic” didn’t just mean “in the right category”. It meant the page was about the exact thing being asked. Take the query “best running shoes for flat feet”. A page genuinely about running shoes for flat feet beats a general “best running shoes” page that never mentions flat feet, even though both are clearly about running shoes. The model could tell the difference, and it almost always picked the page that matched the specific question.
That is why this is a coverage decision rather than a writing trick, and it’s the opposite of a quick fix. You cannot match a topic you haven’t actually covered. If buyers in your niche ask thirty different versions of “which one should I get” and you have three broad pages, you are off-topic for twenty-seven of those questions, however well written those three pages are. Winning citations across a niche means having a page that genuinely answers each real question your buyers ask, not one page straining to be about everything.
The practical starting point is finding those questions in the first place, and you don’t have to guess at them. A tool like AlsoAsked pulls the live “People Also Ask” questions around a topic and shows how they branch off each other, so you can see the actual questions people search rather than inventing them. The harder judgement is what to do with that list: which questions deserve a page of their own, and which fold together. That is the difference between coverage and clutter, and it is worth getting right.
Name a price. Remember that every question here was a buying question, so a price was relevant to all of them. Simply stating one, versus leaving it off, was among the strongest factors in the study. Picture two identical reviews of a £399 robot vacuum: one lists the price, the other says “check the website for current pricing”. On Gemini and Claude the priced page was a near-certain winner. To an AI answering “how much is it and is it worth it”, a page with no price is an incomplete answer, so it reaches for the one that actually answers the question.
The same logic bites harder in B2B, where every page that hides its pricing behind “contact us” or “book a demo” is handing the citation to whichever competitor publishes a number. The fix isn’t always a full price list: a range, a “from £X”, or a worked example of typical cost all beat silence. And to be fair, if a query has no buying intent (“how does X work”), this gatekeeper simply isn’t in play. But the moment a question is about choosing or buying, a real number beats nothing.
Look recent. A page dated 2026 beat the same page dated 2019 by a wide margin on every model, from roughly 14 times more likely on the least sensitive one up to a near-certainty on others. Same content, different date stamp, very different odds. The model treats an old date as a staleness signal. Putting a genuine, current “last updated” date on the pages you care about, and actually keeping them updated, is one of the cheapest wins on this list.
Show up first. This needs unpacking, because the test was not run on Google. The researchers handed the model the two competing pages directly, as a short list of two sources, and varied which one was placed first. The source listed first got cited far more often than the one listed second, even when the two were identical. It is the same bias people have when they skim a list: the top entry gets the attention.
So in the experiment, “first” simply meant first in the little list of sources the model was shown. In a real answer engine, that list isn’t handed over by a researcher. It is built by the underlying search: the AI runs a query, retrieves a handful of pages in ranked order, and reads them in that order. So “show up first” translates to the old job of ranking near the top, because the page the engine pulls in first carries that head start into the citation. This is the one gatekeeper you cannot fix by editing the page. It is earned through retrieval and SEO.
After those four came a second tier of factors that genuinely helped, but only once the gatekeepers were in place. Get the four wrong and none of these save you. Get them right, and these are how you pull ahead of the next page that also got them right.
The next tier: what helps once the basics are right
The four gatekeepers decide whether you are in the running. These next five decide who wins between two pages that both cleared the bar. The study measured each the same way, two near-identical pages with one factor changed, and none of them are formatting. Every one is about what the page actually says.
Include the specifications. A page that listed the technical detail (the numbers, the dimensions, the battery life, what it works with) beat the same page with the specs stripped out, and not by a little. On some models the version that stated its specs was hundreds of times more likely to be cited. If you sell a thing, put its actual numbers on the page. Vague description loses to concrete detail.
Go deep, not thin. A thorough page beat a shallow one comfortably, and on some models by an enormous margin. This is the finding that rewards depth over breadth, and it feeds straight into the one-page-or-many question I come to next: one page that genuinely works through the question beats three that skim it. It is also why churning out thin, near-identical permutations backfires. The model can tell the difference between a page that covers a topic and a page that merely mentions it.
Back your claims. Pages that supported their claims with evidence (test results, certifications, real sources) beat pages that simply asserted things. Most models favoured the evidence-backed page by a meaningful margin, and one of them favoured it overwhelmingly. “Best battery in its class” is an assertion. “Lasted 14 hours in our test, the longest of the six we tried” is evidence. The second one earns the citation.
Say it with confidence. This was the strongest of the secondary factors. Confident, direct writing beat language stuffed with hedges (might, possibly, could, in some cases), by as much as 600 to 750 times on Gemini and Claude, though far less on the GPT models. Hedged writing reads to the model the way it reads to a person: as a page that is not sure of itself. That said, this is a reason to write plainly about what you genuinely know, not a licence to overclaim. State what is true, and state it without flinching.
Compare yourself to the alternatives. Pages that openly compared themselves to other options beat pages that pretended the alternatives did not exist. The effect was smaller than the others, somewhere between roughly 1.5 and 7 times depending on the model, but it points the same way. A buyer choosing between options is better served by a page that addresses the other options, and the model knows it. Naming your competitors and explaining where you fit is not a risk. It is a citation advantage.
None of these are exotic. They are what a genuinely useful product page has always had: real specs, real depth, real evidence, a clear point of view, and an honest comparison to the alternatives. The study just confirms the AI rewards the same things a careful buyer would.
One page or many? How to decide
The topic-matching finding sounds like it commits you to a separate page for every variation a buyer might type: “best running shoes for flat feet”, then “under £200”, then “under £100”, then “for arch support”, on and on forever. You don’t need that, and the test for whether to split is simple. Does the answer change?
If the shoes you would genuinely recommend for “flat feet under £100” are a different set from “flat feet under £200”, those are different questions and earn their own page, or at the very least their own clearly-answered section on a bigger page. If the answer is basically the same list, keep it as one page. Splitting it just creates thin, near-identical pages that compete with each other and dilute the topic. The quick way to check is to run both queries, in Google or in the AI itself, and see whether the answers and the cited sources overlap. Heavy overlap means one page covers both. Genuinely different answers mean genuinely different pages. Doing that overlap check by hand across hundreds of queries is the job we built Keyword Insights around: it groups keywords by how similar their actual search results are, which is the same signal, just automated, and it shows you where to merge pages and where to split them. Weigh my bias accordingly. As a rule, depth on one strong page beats ten shallow permutations, which is exactly what the study’s comprehensiveness factor rewarded.
The advice that did almost nothing
Reformatting a dense wall of text into tidy, well-structured sections did nothing, and that should annoy a good chunk of the industry. Across the six models the effect ranged from 0.78 to 1.68 (remember, 1.0 means no difference at all), and on three of the six models the dense version was actually the slight favourite. Statistically, it was a coin toss. The researchers were blunt about it: formatting choices “had no impact,” because the models parse the meaning of your content regardless of how it looks on the page.
“Restructure your content for AI” is one of the most commonly sold GEO services right now. The data says the model barely notices. It reads what you said, not how neatly you laid it out.
This is exactly where the finding gets twisted into a worse one. It does not mean formatting is pointless. Clean structure still helps the humans who read your page, and good structure often comes bundled with the things that do matter, like clear specs and direct answers. It means that polishing your formatting while ignoring price, dates and topic coverage is rearranging deck chairs. You are spending effort on the one lever the research could not get to move.
The study separated how a page looks from what it actually says, and only how it looks came back as no effect. What it says mattered enormously. One of the factors they measured was the “keyword gap”: whether the page actually contains the words and ideas the question uses. Closing that gap helped on all six models, making a page somewhere between 6 and 40 times more likely to be cited.
So being explicit is not the same as reformatting, and it’s one of the most useful things you can do. Take a vague landing line like “we help e-commerce stores convert more customers”. Rewrite it to be explicit, “Flair helps Shopify stores convert more customers by adding urgency and scarcity to product pages”, and it now names the platform, the mechanism and the outcome. Nothing about that is a formatting change. It’s a content change, and it’s exactly the kind of specificity the research rewards. Vague text doesn’t match a specific question. Explicit text does. If you change one thing after reading this, make your pages say plainly who they are for and what they do.
The catch worth understanding
This study tested one specific moment.
Every test started with both pages already in front of the model. So what it measures is the last metre: given that two pages have already been pulled into the answer engine, which one wins the citation. It does not measure how you get pulled in to begin with.
That first step, getting retrieved into the shortlist at all, is still a search and SEO problem. The paper says so directly: if your brand isn’t showing up in the AI’s sources at all, the bottleneck is retrieval, and the fix is the unglamorous old work of being findable. The gatekeepers in this study decide who wins once you’re in the room. Getting into the room is a separate fight, and it’s the one position bias quietly points back to.
So the honest read is not “SEO is dead, just add a price.” It’s that there are two doors. SEO and findability get you through the first. Topic, price, recency and substance get you through the second. Most people are polishing the doorknob on a door they haven’t reached yet.
A few more caveats worth stating plainly, because the piece is weaker without them. The paper is by a team at Sprinklr and was piloted inside Sprinklr, so it’s a vendor with a workflow to sell, though the method is published in full, was peer reviewed and accepted to SIGIR (the main academic conference for search and information retrieval), and stands on its own. They tested exactly two pages at a time to keep the experiment clean, whereas a real answer engine might weigh five or ten. And they stripped out brand names, which means a strong, trusted brand could still pull rank in the real world in a way this study deliberately switched off. None of that overturns the findings. It just sizes them.
So what do you actually do
This study hands you a priority order. Most GEO checklists are 40 items long and treat everything as equal. This one tells you what to fix first.
- Start with the four gatekeepers. For any page you want cited, check it answers the exact question being asked, states a real price (or a real range, anything beats “contact us”), carries a current date, and is actually findable for that query in the first place. These are mostly editorial fixes you can make this afternoon.
- Then add the differentiators. Once the gatekeepers are sorted, this is where specs, depth, evidence and comparisons earn their keep. Add a spec table. Put a real number behind every claim. Compare yourself to the obvious alternatives instead of pretending they don’t exist.
- Stop spending your time on formatting alone. Tidy it for your human readers, then move on. It is not the thing winning or losing you citations.

So how do you know if any of this is working? You check whether you’re actually getting cited. Run the buying questions that matter through ChatGPT, Perplexity, Google’s AI answers, and see whose sources come up. If you’re not in there, you’ve got a retrieval problem. If you’re in the sources but never the recommendation, you’ve got a gatekeeper problem, and now you know which levers to pull.
Doing that systematically means some form of prompt tracking, and I know that’s a dirty phrase to a chunk of my peers. Don’t get me wrong, there’s plenty wrong with prompt tracking. The numbers are noisy, a single run is close to meaningless, and I’ve written a whole piece on how easy it is to read random wobble as signal. But thrown out entirely it leaves you flying blind, and read correctly (enough prompts, repeated runs, trends over weeks not days) the data still tells you something true. The tool isn’t the problem. The interpretation is.
Where I land
For two years the GEO conversation has been obsessed with the shape of the page. Headings, chunks, structure, formatting for the machine. A quarter of a million experiments just suggested the machine was never really looking at the shape. It was looking at whether you were on topic, whether you answered the buyer’s actual question (price included), whether you looked current, and whether you turned up at all.
That last one is the tell. It’s not a new game bolted onto SEO. It’s the same game it always was, which is being genuinely the best, most complete answer to a real question, and being findable enough to be in the running. The AI just made it brutally obvious when you’re not.
If you want help working out where your brand is losing citations and which of these levers to pull first, that’s what I do.